以用户为中心的设计 |
这是UCDChina提前预览网页留下的存档,不包括作者可能更新过的内容。 推荐您进入文章源地址阅读和发布评论:http://cdc.tencent.com/?p=6306 |
||
|
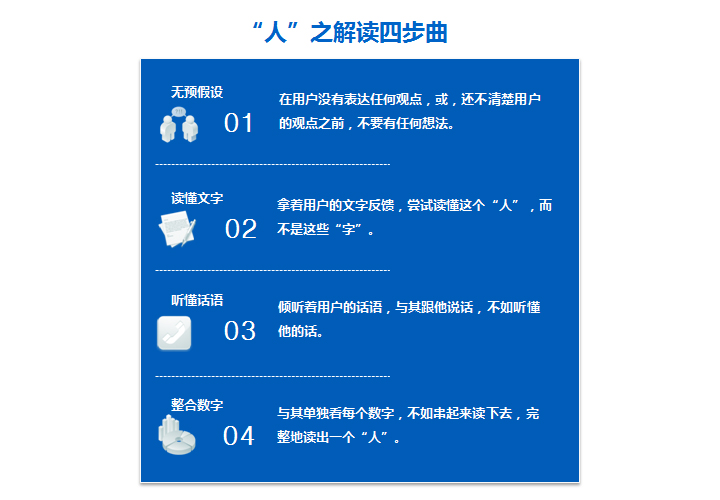
一提到“数据”,可能经常会想到“数字”、“图表”、“模型”、“方程”等容易让人怯步的词语。其实“数据”的真正意义,是躲在背后的那些“人”。 在营销学中,市场的根本在于需求,需求由人而生。因此,我们不应该就数字而数字,就算法而算法,应该自始自终关注“人”,市场研究则更是如此。 有人也许会说,“人”可不好说,有时说谎,有时偏私,真真假假。但,不是有种更简单的想法吗?我们自己本身就是“人”。作为市场研究者,大可不必将自己完完全全剥离在“人”这个概念以外,顶着看似客观的立场,作困兽之斗。 这个时候,也许有人会质疑,如果加入更多自己的想法,你的研究还客观吗? 没错,作为市场研究者,必须客观地看待事实,呈现事实。但事实是什么,如果总把自己孤立在另一边,恐怕这个所谓的事实,也不过是披着云雾的谜团。 在这里,我必须强调,事实的重要性,正是为了看清事实,我们必须“有方法”地在某些情况下,将自己看成是同一边的“人”,某些情况下,将自己独立为另一边的旁观者。 这个“方法”,正是这篇文章试图总结的东西。 1. 在用户没有表达任何观点,或,还不清楚用户的观点之前,不要有任何想法。 我们不妨恶俗地将自己比喻成“蛔虫”,主人都还没有想法,就算你是肚子里的蛔虫,也不可能会知道些什么。 2. 拿着用户的文字反馈,尝试读懂这个“人”,而不是这些“字”。 当问卷回收了,我们“看到”主人们用“文字”写下来的话。这就有两个问题: 这个时候,我们作为同一边的“人”,可以出现了。 举个简单的例子,有两个玩家同时说,你的游戏太耗钱了。请好好看看他们的等级,他们的角色,他们的收入/职业等背景信息,你可能会发现一位是中级,一位是高级,一位是肉盾,一位是魔法师,一位是学生,一位是蓝领。 我们试着代入,如果你是中级肉盾,在这个游戏中会面临怎样的情境?因为游戏规则,你常常与高级玩家PK,结果是PK时常常输掉(挫败感过强),归根到底是因为你的角色只是中级,然后会想“如果我练到高级了,就不怕跟高级玩家PK。”最终,频繁花钱练级,花了钱,却发现永远不可能追上高级,那时正好有个问卷弹出来,你毫不犹豫地说“这个游戏太耗钱了”。 另一个角色,如果你是高级魔法师,因为你等级高,攻击力强,很多人组你打副本,副本对你而言很简单,但手机端的页面总是复杂而庞大,一晚下来,流量用了一半。第三晚开始,队友喊你,你就得用套餐外流量去参与同盟军。两个礼拜之后,月结日发现话费用了100块在超出的流量上,这时你收到一个问卷,你义愤填膺地说“这个游戏太耗钱了”。 上面的例子是想说明,当你读懂了文字背后的那个人,你会发现前者的“耗钱”根源很可能是玩法的成就感缺失,后者的“耗钱”根源很可能是页面的联网响应,二者讲的可能完全不是同一回事。 3. 倾听着用户的话语,与其跟他说话,不如听懂他的话。 有人可能会细心地看到,上面我用了“可能”下结论,说白了,这种代入只是“猜”,你没有任何证据证明这个假设是对的。 没错,不记得哪位名家讲过“大胆假设,小心求证”。如果说前面是如何用“代入”来大胆假设,后面则是如何用“代入”来小心求证。 有了一些粗糙的想法后,作为市场研究者,内心充满了激动和好奇,没有人比我们更想知道自己的假设或想法,到底对不对。这个时候,千万注意,收起我们的激动和好奇。这种先入为主的情绪会成为我们发现事实的障碍。 前面只有文字接触,接下来不妨亲自与用户对话,形式是多样的,电话,面访,现场测试等等。用近乎苛刻的连环追问(这里有技巧,追问的代价绝不能是用户厌烦),让用户自己把自己挖透彻,这个过程可能是痛苦而艰难的,所以你的“代入”变得很重要。只有让用户感觉到,作为同一边的“人”的你存在,他才会愿意做挖掘自己这种艰难的活儿。 案例分享:桌面上放着几款不同品牌的,容量相同材质不同的奶瓶。 请一位中低收入家庭的全职妈妈在挑选的两个中最终选出一个,并且说出原因。两个备选的奶瓶分别是:高端品牌PP材质、一般品牌玻璃材质。最终她选择了一般品牌玻璃材质。她告诉我们,PP材质不知道对小孩好不好,而且自己是全职妈妈,可以照料玻璃材质的,玻璃更安全。 有了这个想法,追问她“送人吗?还是BB用?送人我给你包装一下,BB用的话可能加个把手好一些。” 4. 与其单独看每个数字,不如串起来读下去,完整地读出一个“人”。 从开放式问卷的广度,到与用户对话的深度,我们一直在拼凑和补充材料,“代入”除了帮我们读懂“人”以外,也帮我们描绘了可能存在的问题,可以通俗地理解为“准备上桌的菜”。这个菜到底能上不能上,材料是不是最终做出这个菜,还得继续“小心求证”。 来到定量问卷阶段,将你的材料组织好,送到用户面前,让他们决定,他们想要什么。用户反馈回来之后,我们进入数据清洗、分析、解读阶段。 这里说一下“解读”。 送到我们面前的是一堆数字,一堆图表,我们任务不是告诉大家这个数字是多少,而是数字代表什么。 第一件要做的事是,将自己每种假设的相关数字聚集起来,考察它们是否可以串成链条(俗称“证据链”),如果可以,很好,假设成立。如果不可以,研究一下,假设的漏洞在哪里,也许会发现一个新的结论。 第二件事是,将用户视角下的诸如行为路径、态度轨迹、需求满足过程等链条相关的数字串联起来,看看是否能完整描绘出“人”的形象。如果可以,很好,又一个结论浮现了,如果不可以,检查一下矛盾或缺漏点在哪里,也许会发现用户分类方法不对,另外一个细分维度可能更有效。 举个简单的例子,你有用户对皮肤的元素、颜色、风格、主题的偏好,串联起来,加上一个合适的细分维度对比分析,会发现年龄不同的用户,社会沉浸经历不同,总体风格偏好也存在差异。再类推延伸一下,会发现社会沉浸经历可能会投射在更多其他领域的偏好上。 有人可能会问,这里好像没看见“代入”。其实,在你做的两件事里面,就已经有“代入”。组织证据链、剖绘形象人这两件工作,需要很好地读懂选项占比以及填选项的人,才能做好。 (本文出自腾讯CDC博客: http://cdc.tencent.com/?p=6306) |