本司日前购入T牌眼动仪一台,乃最新型号,无需戴头盔,用户以最自然的状态进行测试。

 很好很强大吧?
很好很强大吧?
一直以来对“神秘”的眼动仪及眼动技术都持敬仰状,可是真正接触并使用就发现陷阱多多 !本文从菜鸟眼动研究实践者的角度出发,试论以下几个问题:
!本文从菜鸟眼动研究实践者的角度出发,试论以下几个问题:
- 眼动研究及其结果的危险
- 眼动研究设计的若干雷区
(1)你是否清楚自己在做哪种类型的研究?
(2)研究过程中的QC
要说明的是:
- 关于眼动研究是什么,为什么要做眼动研究,已有大量文献(见延伸阅读1-3),本文不是讨论眼动研究有多女子多弓虽大。
- 本文讨论背景是企业环境中的眼动研究,非科研机构的眼动研究;
- 本文仅探讨互联网领域的眼动研究,不涉及广告(平面或多媒体)、货架管理等领域的眼动研究
- 本文专注于眼动研究方案的设计及操作过程,暂不讨论对眼动结果进行详细分析时的问题
————————————————————————————
- 眼动研究及其结果的危险
尽管眼动仪设备的精度、追踪技术的可信度、眼动算法等硬件上的局限性目前仍然存在,但眼动研究以其相比起别的人机交互研究方式的“高贵性”(一台动辄几十万淫民币),容易造成盲目崇拜,觉得花了大钱买来的东西,一定很了不得很牛掰。可事实上,如果操作不当(下文将详述),眼动研究结果可能比廉价的可用性测试还不如。
另一方面,眼动数据分析工具,即目前普遍使用的T家的Studio软件,在快速生成貌似直观易懂的数据可视化图方面愈趋强大。随便抓个人来眼动一下,再按一个按钮,一副美丽的数据结果图就能出来!!不费吹灰之力 这样可能造成的危险是,一个设计得很烂的研究,也能做出漂亮的、让老板一看就“懂”的数据结果。最典型的莫过于热度图:
这样可能造成的危险是,一个设计得很烂的研究,也能做出漂亮的、让老板一看就“懂”的数据结果。最典型的莫过于热度图:
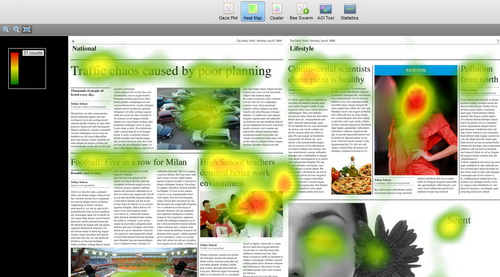
呀,最红的最吸引眼球嘛!傻逼都能看懂
但实质上,热度图可以通过三种计算方式(凝视次数、绝对长度、相对长度)来呈现,每种计算方式的起算点也可以人工设置。选择哪一种计算方式、哪一个起算点,都会影响到某区域的红或不红。其次,时间段对于红与不红也有很大影响。你切前0.5秒和前1秒,也许就变样了。再其次,被试人数能严重影响红分布和红浓度。再再次,红只是表象,导致红的本质是什么?如果研究控制不当,也会严重扭曲结果。
你的老板也许见红就爽,他的确不会知道,也不会关心红怎么来。而且相比起干巴巴的可用性测试结果,精美、“客观”的眼动研究结果,似乎更具卖相。但研究者绝不要贪一时之快,把眼动结果当作忽悠的工具。
- 眼动研究设计的若干雷区
就算你的研究态度刚正不阿,没有科学严谨的研究方法论也是白搭。
雷区1:是否清楚自己在做哪种类型的研究?
互联网行业的眼动研究大致可分为两种——
(1)观察性研究(observational studies):
观察性研究往往作为可用性评估的辅助,找出某一个设计方案的失败/成功之处(见延伸阅读4),或对比某几个设计方案(见延伸阅读5-7)。观察性研究得出的是描述性数据(Descriptive),这种结果不具备普遍性,也不能建立任何因果论(causal link)。并不是说这种研究的结果不可信,只是有局限性,权当参考。对于那种试图推导“模式”的研究结果要特别小心。例如像这篇《科学设计你的网站网页》(译文、原文),用小样本的观察性研究,试图推导大概念。Nielson著名的F-Shape阅读模式眼动研究,之所以要找200多个被试,测试上千网页,就是因为并非实验研究。要得出稍具效度的结论,须大量增加被试数(见《为什么眼动研究需要50个被试》,译文,原文)。
(2)实验研究(experiments):
实验研究是指对自变量(IV)进行控制,并通过严格定义IV、因变量(DV)、严格控制标准化的实验程序,从而得出某个或多个因果联系。实验研究得出的数据具有预测性(predictive)。通常一个实验研究应包括:假设(hypothesis)、设计、被试、仪器、程序、任务。
设计涉及到对IV、DV的定义,采取组间还是组内测试。组内测试涉及到对变量水平(condition)呈现次序的平衡,组间则需要更多的被试人数。被试则是取样了,尤其是人数。但由于是实验研究,可以相对较少,取决于IVXDV有多少。由于每个被试都应经历一模一样的实验过程,对程序的定义也很关键,力求无偏。
值得一提的是任务。实验型眼动研究的任务最好追随KISS原则:keep it short & simple!任务耗时太长或太多,一方面会引入预计之外的不可控因素,另一方面对电脑的数据存储、计算压力很大。尽可能划分子任务,而不是丢给用户一个可能耗时半小时的事做。
为比较以上两种类型的研究,举一个例子。对于下面这幅广告图——

通过观察性研究(如让被试随意浏览),可以知道哪个商品最快吸引视线、文案还是图片让人看得久…等等。假设我们发现红瓶子的最快吸引视线,而想知道是什么因素导致这种情况:是颜色?位置?文案?数字?这就必须通过实验研究来验证。变量、变量水平多到 吧?(详细过程请参考研究方法论等书籍)
吧?(详细过程请参考研究方法论等书籍)
雷区2:研究过程中的QC
以下是在实践中的一些经验。展开眼动研究过程中很有不少突发因素(如一次测试中网页突然加载很慢,用户盯着看、用户手机突然响了、电源线突然松脱了 小声告诉你哦,真的发生过不少次),以及因原本预计不足而造成的客观因素(如用户理解不了任务,边做边问或更离谱地去做了别的任务)。为保证数据干净,有以下几个小建议:
小声告诉你哦,真的发生过不少次),以及因原本预计不足而造成的客观因素(如用户理解不了任务,边做边问或更离谱地去做了别的任务)。为保证数据干净,有以下几个小建议:
(1)牢牢插稳那些电源线、USB线、火线@#¥%……&*,不然突然黑屏会有吃苍蝇的感觉哦!
(2)在正式任务开始前加入仿拟真实任务的练习任务。这是为了保证第一个任务的数据不受影响。通过练习任务,用户可以厘清ta要干嘛,你也可以搞清楚ta到底真懂还是假懂了任务。
(3)事前做好编码模式(coding schema,如F1=用户使用了筛选器,F2=用户使用了类目缩减,etc)。良好的编码能够帮助后期快速处理数据(否则一段段视频看来会疯掉),尤其是解析一些怪异数据。但由于手提电脑处于双屏监测会使运行变得极慢,因此根本用不了按快捷键自动记录编码。目前俺们使用人肉记录 ,还是比啥都不记录要好。
,还是比啥都不记录要好。
(4)让用户事后回溯,即所谓PEEP(Post Experience Eyetracked Protocol)法。眼动结果是干货,有了用户的点评才是点睛。这与任务长短息息相关,你总不能让Ta回溯老半天。所以任务也是短小精干好!
(5)让用户歇歇 要保持那个该死的姿势,死盯着那该死的屏幕,做那些该死的任务,还没完没了的,人家容易嘛?中途歇歇,有利于数据质量,有利于用户健康!
要保持那个该死的姿势,死盯着那该死的屏幕,做那些该死的任务,还没完没了的,人家容易嘛?中途歇歇,有利于数据质量,有利于用户健康!
亲爱的读者,能坚持看到这里,您的眼睛也累了,谢谢!!春天到了,多出去运动运动吧
延伸阅读——
- 眼动仪大全
- UCD社区的眼动仪话题
- 腾讯的眼动仪
- Google对SRP的眼动研究
- 客户管理软件新旧版对比
- “Is your design clear or confusing?”(译文,原文)
- Evaluating the Usability of Search Forms Using Eyetracking(译文,原文)
参考文献——
By Andrew T. Duchowski





