上周参加碳酸分享,趁机对设计师进行了小小的“调研”。当然,8个问题,16个设计师,说“调研”有点 只是希望更好地了解一下提出测试需求的设计师们——也就是我们的“客户”,也为接下来的工作提供指引。
只是希望更好地了解一下提出测试需求的设计师们——也就是我们的“客户”,也为接下来的工作提供指引。
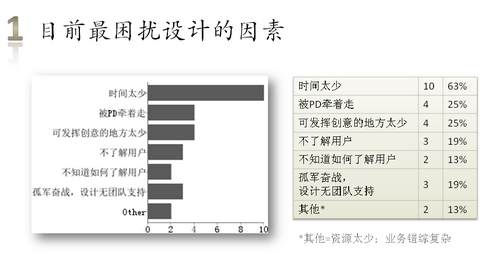
(由于用的是google的表单统计摘要,图表没法排序,有点恶)
时间很少,需求很多,设计师都很辛苦哦。

上次用户测试前看项目的PRD(产品需求文档),总觉得非常以功能为中心。遂萌生了了解设计师如何看待的想法。结果跟我的感觉差不多。那么,用研组是否合适去承担,辅助产出用户使用场景(Scenario)和Persona的工作?
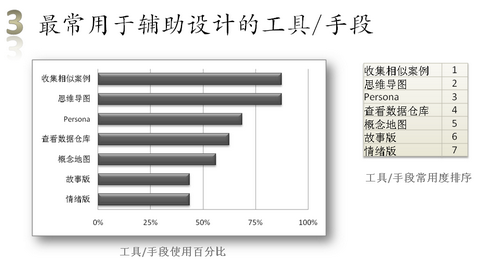
这道题让设计师勾选TA所使用的工具/手段,并排序。
既然收集案例是绝大部分设计师都做的事情,那一个内部的案例共享库,会不会有用呢?
有意思的是,有一半以上的人将Persona列为常用辅助手段,且是第三常用的,我就好奇了,这些Persona是以什么形式存在的呢?似乎从没见哪个项目产出过Persona哦。那是否意味着Persona仅仅存在于设计师脑海?存在于脑海的话,其实是否就已足够呢?

可用性测试平均排名为首,这是很正常的,因为耗时最短。大家对实地考察的兴趣蛮浓厚~~~我也很期待!

哈哈,有趣的结果哦!用户使用心得日志竟然排在第一了!也许是因为大家感觉这种反馈最真实?
其实,之前已在考虑做这种人种学形式的体验案例收集,只是困难包括周期长,数据提取、总结较复杂等。当然,人种学式的用户研究还是很希望有机会做的。

6个人测试为什么就足够,看来我们还是没有好好传达出去。对于定性和定量的区别,实在很tricky,但是想明白了,还是很清晰的。
至于测试任务,我们也很头痛呢。记得我看过一个设计师说他认为测试的环境太假,用户在假环境中做着假任务,只会给设计师制造假象。的确,仿真程度往往与测试严谨性是互斥的。但可用性测试并不是也不可能发现所有问题,比起AB Test或投放试用版,它能更廉价、更高效地发现可能存在的问题。经验看来,即使在假环境中做假任务,也能做到这一点。这些问题未必有普遍性(因为样本小,无法推论),但问题既然发生,那么通过分析原因——包括用户本身的个体差异,是否违反设计规范、经验准则等,就能较好地判断设计是否不妥,或者是否能进一步优化。这也是为什么6个人就足够的原因之一。用一个简单的方式理解就是,可用性测试不是要论证问题的普遍性,而是试图发现可
能会被用户普遍遇到的问题。AB
Test确实能从数据上证明版本的优劣,但它并不能告诉你,A为什么比B好,B是否也有比A好的地方。而让6个用户试用A和B版本,尽管不能用“5个用户
觉得A比B好”来证明A就是比B好,但至少你更有可能发现A和B各自的优缺点,从而产出一个更完美的C来。

对于报告的撰写,我们一直在探讨,并努力改进。目前结果看来,与我们努力的方向还是一致的,只是仍需努力
记得前周一个培训上,一位交互设计师提到,希望用研童鞋的报告“把问题写得严重点,但表达得委婉点”。就是说,动之以情晓之以理是吧?要照顾设计师的情绪,又不能不指出问题,的确有点难度 可是,我们会迎难而上滴!
可是,我们会迎难而上滴!

每一个项目的测试,对我来说都是向设计师学习的机会。而我们这群从来不设计,却老去挑人家设计毛病的用户研究员,的确应该提供更多“服务”(如上面提到的使用情景、Persona等)。只不过由于沟通的缺乏,我们往往被排于设计的主流程之外,只是在最后的时候来插一脚。
最后一道是开放性问题,“想对用研童鞋说的话”。大家的“加油”我们看到了,大家的期望和指教也看到了。让我感动的是这句话,“我信任你们的团队”。信任是最大的支持和鼓励,也是最大的鞭策——因为不可以辜负这种信任哦!
未来的大方向,就看伟大领导轻侯同学的指引了。至于我自己,目前将致力把国际化的研究方法山寨化





