以用户为中心的设计 |
这是UCDChina提前预览网页留下的存档,不包括作者可能更新过的内容。 推荐您进入文章源地址阅读和发布评论:http://piglili.blogbus.co......60772605.html |
||
|
*本文内容由渡劫、剑虹、和笔者共同提供,笔者整理归纳 TB最近在各个关键产品与购物流程中陆续加入了用户反馈入口(图1),也开设了各种官方论坛收集用户意见和建议,因此会收集到大量纯文本数据。如何对这些数据进行分析、从而指导产品改进?本文将讲述,将内容分析(content analysis)应用于网络文本数据(如,用户反馈)处理的理论基础与实际应用。包括:内容分析法简述;企业中应用内容分析的步骤与技巧。  图1:淘宝的用户反馈 入口 PART1 理论基础:内容分析法简述 内容分析,是指利用明晰的编码规则,将大量文本信息转化为定量数据,并 归于若干类别以分析信息特征的方法)。内容分析有三个特点: 1)客观性。内容分析不受主观偏见影响,有标准化的研究过程,研究员对结果持开放态度; 2)系统。内容分析过程(取样、分析、编码等)有统一、标准的规则和程序; 3)定性与定量结合。内容分析通过定性研究找出能反映内容本质的特征,又将文本转化为定量的数据,分析 结果可用频次、百分比,或相关系数等来表示。 这种研究无需直接接触研究对象,在传播学、情报学、教育学等社会学科有广泛应用,但目的有所差别。鉴于本文所述的应用类型,更倾向从情报学的观点去定义内容分析的目的:通过分析内容了解本质性的事实和趋势,并揭示隐性问题。换句话说,在用户反馈分析中应用内容分析法,目的在于对反馈信息进行系统的归纳分类,整理问题点并评估其严重性,从而有针对地实施改进。 内容分析的基本流程如图2所示。科研中,还有训练编码员(5、6环节间)、测量编码员之间可信度(6、7环节间)的步骤。在企业环境中由于受到时间等调研成本制约,可选择性执行这两步。具体每一步的实施将在PART2中通过实例详述。  PART2
实践应用:步骤与技巧 1)编码员(用户研究员)需要对产品/项目的功能等特征有充分了解;
2)抽样的时间点,会根据产品/项目的特点而定,如有无重大改 进等; 3)分类以及后续数据分析维度的建立,是研究员与产品经理等项目组关键成员共同完成的; 现按照前文所述的分析流程,以旺铺升级后一周内的用户反馈分析为例,介绍内容分析在企业用户研究中的实践步骤。 【第一步 对分析的目标和范围做出准确定义】
 分析目标:收集、归纳用户体验问题及用户看法
呈现在用户研究报告中,也就是一句简短陈述,如:旺铺升级后一周内的用户反馈总结 【第二步 决定抽样样本】  包括决定以下三方面 1)内容源:选择从什么地方(帮派?问卷?…等)抽样 这意味着研究员要对产品周期有充分的了解和认识。在本例中,我们的抽样样本是,旺铺升级后一周内 (7天)用户通过旺铺装修页面“提意见”入口(图3)提交的所有数据。
图3:旺铺用户反馈收集入口 【第三步 确定分析单位】  分析单位是内容分析中的最小元素, 要对此给出明确清晰的操作性定义。在本例中,分析单位就是一名用户所陈述的一条意见。值得注意的是,并非以一次提交的数据为单位,因为一名用户一次性可能 提交若干条意见,需要把意见拆开,每条为一个分析单位。如图4所示,“删除模块删完不能添加”、“发布完又回到装修页面”分别是一个分析单位。  图4:分析单位举例 【第四步 建立分类】 
分多少类为合适?类别太多会导致某些类的分析单位少而失去统计意义;类别太少,不同性质的分析单位归入同一类,可能会掩盖显著性差 异。考虑到将分类合并比将分类拆分容易,建议宁多勿少。在无从下手的情况下,可试检验50-100条分析 单位。 在本例中的分类如图5——  图5:旺铺用户反馈 的分类与说明 该分类倾向于以问题解决方(如系统问题由开发人员解决、功能需求由产品经理解决、交互问题由设计 师解决)为基础维度,便于推动改进。对于页面、功能有限的产品/流程,也可按照页面或功能分类。对于本例,也有针对功能、页面进行分类,主要体现在二级编码中,详情见下。 【第五步 制作编码表 试验性编码】  制作编码表是在大分类的基础上进行 细化,以更好地聚焦问题。在这一步,要尽可能细致全面,才能保证有效的数据分析。对每个编码的含义要有所说明,尤其在编码者不止一人的情况下。在本例中, 对功能需求这一大分类的部分编码如图6,其原则是尽可能涵盖所有功能。而对于系统问题、交互体验问题,子编码 又是应内容特点、以另外的维度设定的。 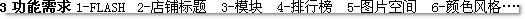 图6:编码表示例 在
编码表制作好后,抽取50-100条分析单位(如100条反馈)进行试编码(coding),以检验是否够细够全。当然了,在实际实施编码(第六步)过
程中可能发现编码不够用的情况。此时只能新增编码,并对该分类下的所有分析单位重新编码。所幸的是——也是内容分析的优点之一——即使发现问题,能在不影
响数据本身准确性和完好性的情况下弥补错误。不像问卷调研或现场实验,一旦实施,有错误也无法弥补,只能抛弃数据。  收集数据就是按照之前所定义好的范围与抽样 标准提取数据。通常将数据导入到EXCEL中进行处理。在本例中,每条用户意见(即最小分析单位)对应一行(图7)。  图7:原始数据示例 然
后便可开始对每个分析单位进行编码,是纯人工的过程。目前也有一些文本分析软件可辅助,但这些基于分词技术的软件智能程度不足,且实施聚类分析对样本量有
要求(至少上万条),更适合用于海量文本数据的分类。  图8:文本筛选功能 示例 初步编码结果如下图所示,接着便可进入分析、报告阶段。  图9:编码结果示例 【第 七步 分析 报告结果】  分析包括两部分。定量部分使用描述性统计,计算各分类中条目、各个码类的频数、百分比。如果还能结合到其他变量,如用 户的星级等,可进行更复杂的交叉分析、卡方检验、t检验、方差分析等。定性部分,是对某子编码下的所有条目进行梳理,总结出问题点。 要注意的是,频数、百分比不是衡量严重程度的唯一指标。比如我们发现大量系统问题这一分类的用户意见,但基本上说 的只是发布失败和速度慢两点。 功能需求这一分类下的意见总数相对较少,但问题有10余种。因此,定性与定量分析的结合,才能反映各分类对整体体验(满意或不满意)的贡献度大小,以及问题聚焦/分散程度。示例如下:   图10:反馈总结示例 进 一步的分析还包括对表象所隐含的问题的推断。例如笔者发现图11所示的问题。  图11:深层分析示例
小结 |
 ——>
——>